Welcome to December, friends of Red. It's an intent and focused time of year as we wind down 2019, and the core team is making important moves (sometimes literally!) to set us up for an ambitious 2020. But first, here are just a few things that happened in November.
First and foremost, it's always great when community members help compile resources for use by others, and we'd like to acknowledge @rebolek for his excellent compendium of historic automatic builds: https://rebolek.com/builds/ (they weren't available for a hot minute, but now they're back). They can be useful if you're in need of a previous version for a specific project. Of course, you can always go here for Red's daily automated builds. But seeing as how we've a goal of being a self-sustaining, self-selecting group of do-ers, this spirit of providing collective resources is perfectly aligned with the Red-Lang we always want to be.
From the community, to outreach: thanks to community member @loziniak, Red is now on Stackshare, so be sure to follow us there and chime in. As a repo with 4.1k GitHub stars (and infinite possibilities), Red has a lot to offer the wider community of developers and engineers, and Stackshare is a great place to help compare and contrast us with other languages.
Now, a challenge! In the coming new year we'll be needing beta testers willing to lend their expertise in refining a new product built with Red. You read that right! If you think you'd like to be one of the contributors to spearhead a move into our next phase, we want YOU! Drop a line to @greggirwin to get in on the ground floor.
An appreciation to @hiiamboris for his deeply thought out proposal regarding "series evolution," a framework for standardizing and testing the functions we use in Red for manipulating series. Design is hard, and we have a number of initiatives in the works taking a lot of brain power right now.
Over 60 commits were made to Red's GTK branch in November, making it almost ready for "prime time." The product of a lot of work by a fair handful of the core team, heavy lifter @bitbegin says that merging to master branch is possibly the next step.
And, to close, a bit of a tease: Watch this space for some snazzy website changes coming soon.
All the warmest wishes for the upcoming holidays, from the Red family to yours. <3
The original commentary was posted in Red's Gitter channel, here, by Gregg Irwin, one of our core team members, in response to various requests for the ability to create new datatypes in Red. As a writer, Red has always appealed to me because of its flexibility; but, of course, "the [lexicon] devil is in the details," as the idiom goes (okay, I edited that idiom a little, but it was too cool a link to pass up). It means the more specific we try to be, the more challenges and limitations we encounter, and we can lose some of the amazing versatility of the language. On the other hand, precision and refinement--the "exact right word at the exact right time," can powerfully enhance a language's utility. The dynamic tension between what he calls "generality and specificity, human friendliness and artifice," in the text below, can be an energetic ebb and flow that serves to strengthen our language, to make it more robust. Two quotes from community members provide some context:
_____________________________
> The real problem is not number of datatypes, but the lexical syntax of the new ones. -@Oldes
> ...However if something likeutype! is added, nothing prevents you from (ab)using system/lexer/pre-load and reinventing whole syntax. -@Rebolek
"I don't support abusing system/lexer/pre-load, and (in the long view) there will almost certainly be special cases where a new lexical form makes sense. We can't see the future, so we can't rule it out. But, and this is key, how much value does each new one add?
I believe that each new lexical form adds less value, and there is a point of diminishing returns. This is not just a lexical problem for Red, but for humans. We have limited capacity to remember rules, and a constrained hierarchy helps enormously here. Think more like linguists, and less like programmers or mathematicians.
In language we have words and numbers. Numbers can be represented as words, with their notation being a handy shortcut for use in the domain of mathematics. And while we classify nouns, verbs, and adjectives by their use, they are all words, and don't have syntax specific to their particular part of speech. That's important because a single word may be used in more than one context, for more than one purpose.
This is interesting, as a tangent, because human language can be ambiguous, though some synthetic languages try to eliminate that (e.g. Lojban). The funny thing is that it's almost impossible to write poetry or tell jokes in Lojban. Nobodyº speaks Lojban. This ties to programming because, while we all know the strengths and value of strict typing, and even more extreme features and designs meant to promote correctness, dynamic languages are used more at higher levels [such as poetry, songwriting and humor, where even the sounds used in one single word can be employed to evoke specific emotive responses in the listener--the effects of devices like assonance, consonance, and loose associations we make with even single letters, in the way a repeated letter R throughout a line of poetry or literature can subtly impart a sense of momentum and intensity to the text...possibly because it evokes a growl... -Ed.]. Why is that? Humans.
When Carl designed Rebol, it had a goal, and a place in time. He had to choose just how far to go. Even what to call things like email!, which are very specific to a particular type of technology. This is what gives Redbol langs so much of their power. They were designed as a data format, meant for exchanging information. That's the core. What are the "things" we need to exchange information about with other humans, not just other programmers?
Do I want new types? I'm pushing for at least one: Ref! with an @some-name-here syntax. It's not username! or filename+line-number!, or specific in any way. It's very general, as lexical types should be; their use and meaning being context-specific (the R in Redbol, which stands for "relative"). I also think ~ could be a leading numeric sigil to denote approximation. It came mainly from wanting a syntax for floats, to make it clear that they are imprecise; but it's tricky, because it could also be much richer, and has to take variables into account. ~.1 is easy, but what about x = ~n+/-5%? Units are also high value, but they are just a combination of words and numbers. (Still maybe worth a lexical form.)
When we look at what Red should support, and the best way to let users fulfill application and purpose-specific needs, we can learn from the past, and also see that there is no single right answer. Structs, Maps, Objects, data structures and functions versus OOP, strict vs dynamic.
As Forth was all about "Build a vocabulary and write your program in that," think about what constitutes a vocabulary; a lexicon. It's a balance, in Red, between generality and specificity, human friendliness and artifice. So when we ask for things, myself and Nenad included, we should first try to answer our need with what is in Red today, and see where our proposed solution falls on the line of diminishing returns. To this end, we can and should abuse system/lexer/pre-load for experimentation."
Several things. It started when @dockimbel looked into ticket #3606, which was impossible to fix currently, and we didn't want to give up on the auto-syncing between /text and /data facets. So he had to consider bigger options, including how to make the lexer instrumentable. It was not easy, because the current lexer is not re-entrant, so having the lexer emit events to a callback function could have caused serious problems.
Digging through all Red's repos showed that the current lexer code was duplicated twice, beyond the basic lexing needed by load: once in the console code, once in the VSCode plugin, each time for syntax coloring purposes, and each one lagging behind the original implementation. Not good.
@Dockimbel then considered changing the current lexer to make it instrumentable, but the changes were significant and would have made the parse rules much more complex. At the same time, @qtxie did some benchmarking, and the result showed Red's lexer was ~240 times slower than Rebol's. This is not due to parse, but rather because the high-level rules were optimized for readability, not performance.
The lexer also caused delays in the VSCode plugin, because of its (lack of) performance. The high level code has served Red well, and was a showcase for parse, but loading larger data is also being used by community members, and data sizes will just keep growing. With some projects we have on the horizon, the lexer's performance became a higher priority.
As planned since the beginning (the lexer used to be R/S-only during the pre-Unicode era), @dockimbel decided the best option was to not postpone the conversion of the lexer to pure R/S code any longer, by porting R3's C-based lexer to R/S. After studying Rebol's lexer in detail, he realized that the code was quite complex in some places (mostly the prescanner), and would lead to less than optimal R/S code that would be hard to maintain.
Evaluating the state of the art in fast parsers for programming languages, he found inspiration in some unpublished papers. He then started prototyping the next lexer in R/S, and realized that it could be several times faster than Rebol's, with the additional benefit of much smaller and simpler code. Then he embarked on the full implementation. Knowing he and @qtxie would not have the opportunity to work on that for probably a year with all the big tasks ahead on the roadmap, he committed to it full time.
Red's new R/S lexer is half the size of Rebol's, far simpler, with more maintainable code, and it performs at similar speeds (sometimes a bit faster, sometimes a bit slower). That is a fantastic result, because it means that with an optimizing backend (Red/Pro), our lexer will be 4-8 times faster than R3's. It should then be possible to load gigabytes of Red data in memory in just a few
seconds (using the future 64-bit version). 😉
An additional benefit was brought by @qtxie, who added a hashtable for symbol lookup in Red contexts. That sped up word loading tremendously, and should have a measurable improvement on Red's start up time; especially on slow platforms like Raspberry Pi.
@Dockimbel is almost done with the lexer itself, just date! and time! to add, and it should be possible to replace the old one with the new one after thorough testing and debugging. Then, we'll add the hooks for a user-provided callback, allowing us to instrument the lexer in ways Redbolers could only dream about until now. One application of that will be the ability to implement "predictive loading," which will tell you the type and size of a Red value in a string, without loading it, and at extremely high speed (~370MB/s currently, 1-2GB/s with /Pro). Such a feature will allow us to finally address the #3606 issue with a very clean and efficient solution, while keeping the facet's auto-syncing feature.
Over the last few weeks the Red Lang core team drilled down to make some truly great progress on Red's fast-lexer branch--while we also gained valuable support from the contributions of Red doers and makers as they consolidate a world of useful information and resources.
Fast-Lexer Benchmarks
In the fast-lexer branch of Red, you can see lots of new work from Red creator @dockimbel (Nenad Rakocevic) and core teammate @qxtie. Among other fixes and optimizations, they substituted a hashtable for what had previously been a large array in context!
The numbers so far: Loading 100'000 words (5 to 15 characters, 1MB file):
Red (master): 19000ms. Red (fast-lexer): 150ms. Nenad's observations on further testing:
"FYI, we just [ran] some simple benchmarks on the new low-level lexer for Red using 1M 10-digit integers. The new lexer completes the loading about 100 times faster than the current high-level one. Loading 1M 10-digit integers in one block: Red: 175ms; R2: 136ms; R3: 113ms.
"We use a faster method than Rebol, relying on several lookup tables and a big FSM with pre-calculated transition table (while Rebol relies on a lot of code for scanning, with many branches, so bad for modern CPU with branch predictions). With an optimizing backend, Red's LOAD should in theory run 2-3 times faster than Rebol's one. (Though, we still need to optimize the symbol table loading in order to reach peak performance). Given that Rebol relies on optimized C code while Red relies on sub-optimal code from R/S compiler, that speaks volume about the efficiency of our own approach. So, Red/Pro should give us a much faster LOAD.
"The lexer is not finished yet, but the hard part is done. We still need to figure out an efficient way to load keywords, like escaped character names (`^(line), ^(page), ...) and month nouns in dates."
This is a huge accomplishment, and it's shaping up to make future goals even more impressive. The fast-lexer branch is a work in progress, but stay tuned: Nenad has more to say about why it's been prioritized just now, which we will have in an upcoming post.
Red's MVPs Contribute New Resource Material & Tools
If you're new to Red, sometimes the flexibility of the language can leave you uncertain about which aggregate structure to use. In red/red's wiki on github, @9214 contributes a useful guide for those seeking to tease apart the differences. For example, map! works better with data that can be atomized, or framed as a conventional associative array, while hash! lends itself to data that will be queried at a high volume and which will require fewer updates. Learn further linguistic nuances, including object! and block!, as well as a useful comparison table of their algorithmic complexity, here. @Rebolek, meanwhile, has furnished us with loads of useful information, diving deeper into code statistics. His value datatype distribution, here, his unofficial Red build archive here, and his rebolek/red-tools repo containing various tools--line parsers, codecs, APIs and documentation among them--are greatly appreciated. The tools repo has a number of new features you can check out here.
About Those Ports...
Wondering about port!? Here's the latest. We've got port! in the master branch already, but low-level input/output networking abilities aren't complete yet, so we need to focus on this, and your feedback can always help. "We have a working async TCP and TLS ports implementation (both client and server-side)," explains Nenad, "but they still require more work to cover all the target platforms." Here, he goes on to explain the prerequisites for our team to complete this process; your thoughts and code contributions are welcomed.
Games and Experiments
It's a fun one to end this update on: Red community member @GalenIvanov's "Island Alleys," a game of unspooling Hamiltonian paths! A path of this type only allows its line, which inscribes a closed loop, to cross through a vertex within a graph once, a process which can lend itself to neural network-related interpretations. And @planetsizedcpu offers a wintry little spin on this repo. Enjoy, and thanks to all!
Hello to all the great makers, doers and creative people who are using Red, helping the Red Language grow and improve!
As always, there's a standing invitation for you to join us on Gitter, Telegram or Github (if you haven't already) to ask questions and tell us about your Red-powered projects.
Here are some recent highlights we’d like to share with you:
1. Tickets Get Priority
In the last month, our core team has closed a large number of tickets.We’d like to thank community members rgchris, giesse, and dumblob who are just a few of the passionate contributors putting Red through its paces and providing feedback as fixes and changes occur. @WArP ran the numbers for us, showing a cyclical growth pattern linking bursts of closed issues and some serious Red progress, and September’s not even done yet!...:
2. CSV Codec Available
Our newly updated CSV codec has been merged in the master branch and is now a part of the nightly (or automatic) build here. It is in an experimental phase, and we want your feedback.
Should the standard codec only support block results, so it’s as simple as possible? Or do people want and need record and column formats as well (using the load-csv/to-csv helper funcs, rather than load/as)? Including those features as standard means they’re always available, rather than moving them to an extended CSV module; but the downside is added size to the base Red binary.
Applause goes to @rebolek’s excellent organization and his wiki on the codec, which explains the various ways in which Red can represent data matrices. He writes, “Choosing the right format depends on a lot of circumstances, for example, memory usage - column store is more efficient if you have more rows than columns. The bigger the difference, the more efficient.”
You can judge their efficiency here, where @rebolek has laid out the compile time, size and speed of each version, including encapping and lite. Be sure to get the latest build, and chat with everyone on Gitter to tell us what you think.
We’re truly grateful for all the interest and support, and we are proud of the way our growth has been powered by this community.
4. AI + Red Lang Stack: Precision Tuning With Local OR Web-Based Datasets
In conversation with @ameridroid:
“Presently, it seems like most AI systems available today either allow building an AI from scratch using low level code (difficult and time-consuming), *OR* using a pre-built AI system that doesn't allow any fine-tuning or low-level programming...with the advent of NPUs (Neural Processing Units) akin to CPUs and GPUs, an AI toolkit would allow specifying what type of AI we want to perform (facial, image or speech recognition, generic neural net for specialized AI functions, etc.), the training data (images, audio, etc.) and then allow us to send it the input data stream and receive an output data stream…[using Red] would also allow us to integrate with the AI system at a low level if we have specific needs not addressed by the higher-level funcs. Red dialects would be a good way to define the AI functionality that's desired (a lot like VID does for graphics), but also allow the AI components, like the learning dataset or output data stream sanitization routines, to be fine-tuned via functions. Red can already work on web-based data using 'read or 'load, or work on local data in the same way; the learning data for a particular AI task could be located on the web or on the local machine. That's not easily possible with a lot of the AI solutions available today.”
Check back in the next few days for an update from @dockimbel!
Ideas, contributions, feedback? Leave a comment here, or c’mon over and join our conversation on Telegram, Gitter, or Github.
As part of the R&D work on port! datatype in port-type branch, we have implemented a GPIO driver for Raspberry Pi boards, as a gpio:// scheme (no third-party library needed). This work helped define the low-level API for ports written in purely Red/System or a mix of Red and Red/System.
The Raspberry Pi is a very popular board with millions of units sold, so this is a market where Red could be potentially helpful to developers. We could run Red on such boards for years but did not have proper GPIO support, so this is now fixed!
The current features supported by the GPIO port are:
auto-detecting the Raspberry Pi board type
uses /dev/mem or/dev/gpiomem for direct and fast access.
reading a GPIO pin state.
writing to a GPIO pin state.
hardware PWM output support (on capable pins).
a simple DSL for sending commands.
Planned (but not scheduled) future features include:
generating events when a pin state changes.
software PWM on all GPIO pins.
a higher-level reactive object layer for a API-less interface.
various drivers for common peripherals.
The source code for the gpio:// scheme can be found there.
In the short video below, you can find a little pet project meant for testing some of the features. It implements a simple joypad with 4 directions support, a red LED indicating when the pad is active and a green one for notifying when a level is completed. The game is the Red port contributed by Huang Yongzhao of Rebox!, my old clone of BoxWorld written in Rebol. In the video below, it is running on a Raspberry Pi 3 using our work-in-progress red/GTK backend for Red (contributed by Rcqls), locally merged with the red/port-type development branch (EDIT: that branch has been merged into master now).
You can find the breadboard layout below made using Fritzing. Sorry for the messy wiring, it is my first try with such kind of tool. If you have the skills to improve it, here is the sketch file. The buttons rely on the internal pull-down resistors. Note that in the video, the board is reversed.
The source code of Redbox has been modified to add GPIO support, you can find the modified code here. The GPIO-related code is enclosed in a context:
joypad: context [
mapping: [
16 down 20 up
17 left 21 right
]
row: [(id) state: #[false] direction: (direction)]
table: collect [
foreach [id direction] mapping [keep compose row]
]
pins: extract table length? row
port: none
acquire: has [pin][
port: open gpio://
foreach pin pins [
insert port [
set-mode pin in
pull-down pin
]
]
insert port [
set-mode 18 out
set-mode 4 out
set 4 on
]
]
pressed?: function [][
foreach pin pins [
entry: find table pin
old: entry/state
insert port [get pin]
entry/state: make logic! port/data
;-- detect 0-to-1 transitions only, to avoid auto-firing
if all [not old entry/state][return entry/direction]
]
none
]
show-win: does [insert port [set 18 on]]
release: does [
insert port [
set 4 off
set 18 off
]
close port
]
]
The GPIO port has a simple API:
opening: port: open gpio://
sending commands: insert port [...commands...]
closing: close port
The sent commands form a small DSL:
Set the working mode for a given pin:
set-mode <pin> <mode>
<pin> : pin number (integer!)
<mode>: in, out, pwm
Write a value on a pin:
set <pin> <value>
<pin> : pin number (integer!)
<value>: true, false, on, off, yes, no, 0, 1
Read a value from a pin (the returned value is in port/data):
get <pin>
<pin>: pin number (integer!)
Manage pull-up/down resistors:
pull-off <pin> ;-- disable any pull previously set
pull-down <pin> ;-- activate pull-down on the given pin
pull-up <pin> ;-- activate pull-up on the given pin
Write a PWM value on a pin:
set-pwm <pin> <value>
<pin> : pin number (integer!)
<value>: an integer between 0 and 1024, or a percentage for duty cycle.
Fade in/out values on a PWM pin:
fade <pin> from <start> to <end> <delay>
<pin> : pin number (integer!)
<start>: starting value (0-1024)
<end> : ending value (0-1024)
<delay>: duration of the whole fading (time!)
Wait for a given duration:
pause <delay>
<delay>: integer => pause in miliseconds, float => pause in seconds.
Important notes
Only BCM numbering for GPIO pins is supported.
A word, or path or paren expression containing regular Red code can be used in place of any numeric value.
A single command block can contain an arbitrary number of commands.
The getcommand can be used multiple times, a block of corresponding results will then be returned in port/data.
Use sudo when running your GPIO code if it involves PWM!
An example of using fadeand other commands is available here.
The PWM range is currently preset to 1024, though, the DSL can be trivially extended to allow a user-provided range value.
We are releasing today the version 0.4.0 of the RED Wallet with several major new features. As a reminder, the RED Wallet aims to be a simple and very secure wallet for the major cryptocurrencies (BTC, ETH, and ERC-20 tokens). Safety is enforced through the mandatory use of a hardware key (Ledger or Trezor keys), which protects against any failure of the wallet app (being it a bug or an attacker). The RED Wallet code is fully written in Red (using the Red/System DSL for USB drivers implementation) and open source.
BTC support
The RED Wallet now supports the bitcoin network. The main features are:
retrieval of address balances.
sending transactions (with follow-up on an online block explorer).
support both SegWit and Legacy addresses.
support both mainnet and testnet.
The balance retrieval can be quite slow on the bitcoin network, so be patient.
ERC-20 tokens support
ERC-20 tokens are supported since version 0.3.0. Though, Ledger removed the ERC-20 tokens list from the embedded Ethereum app since version 1.2.6, leaving it to the wallet app to manage the tokens list. This release now incorporates that list in the RED Wallet binary directly, resulting in a significantly bigger binary (about 100 KB bigger than 0.3.0). The Nano keys will still check the validity of the tokens addresses internally for extra safety. Another consequence of Ledger's recent firmware updates is noticeably slower addresses retrieval when plugging the key. That's an internal change in the Ledger key, so we cannot do anything to bring back the fast speed we could achieve with older firmware.
As a reminder, BIP44 address derivation support is present in the wallet since 0.3.0. If you are using a key initialized in an older Ledger Live version, the derivation path would be different and in order to make the wallet recognize your key, you need to click on the "(Legacy)" label (we will improve that UI in further versions).
Batch transactions were introduced in 0.2.0, they now work for any ERC-20 tokens in addition to ETH. They can be accessed from a contextual menu using a right click on an ETH account.
TREZOR Key
The RED Wallet has updated the firmware support:
Wallet v0.3.0: Compatibility with firmware 1.7.1+
Wallet v0.4.0: Support for the latest firmware of the Trezor key. 1.8
TREZOR model T is fully supported on macOS. On Windows 7, if the key is not recognized, you need to install the TREZOR bridge first.
Bug fixes
FIX: Ledger key does not work on Windows in some cases.
FIX: crashes in some cases when using Ledger key on Windows.
FIX: only ledger key is usable when plugging both ledger key and trezor key.
Just click on the executable to run it (extract the .app file first on macOS), no installation or setup process required. Plug in your Ledger or TREZOR key and enjoy a smooth and simple experience!
If you want to check if your RED Wallet binary has been tampered with in any way, you can simply drag'n drop the wallet executable on our binary checking service. If it's legit, the screen will turn green. If it turns red with a warning message, please notify us on Gitter or Twitter at once.
Only download the RED Wallet app from this page, do not trust any other website for that.
If you are an active member of the Red community, you will have likely been keeping track of Red's progress through our Gitter rooms and Github repositories, but we wanted to officially bring everyone up to speed with a shiny new blog post. The team has been busy since January on many fronts, multiplexing its efforts on many different branches of development. Here is an overview of what we have been cooking and what is coming.
RED Wallet
We are preparing to release v0.4.0 of the RED Wallet which will feature:
Bitcoin support with both Legacy and SegWit addresses!
Updated support for ERC-20 tokens for Ledger Nano keys (after Ledger externalized such token management to the wallet software earlier this year).
Support for the latest firmware of the Trezor key.
Some bug fixes.
The new wallet is currently under heavy testing, we plan to release it publicly in about a week.
C3
The first public alpha of the C3/System compiler is coming this summer. It is still under heavy development though. C3/High has made little progress as it needs real-world use-cases from the smart contract ecosystem for modelling the DSL(s). That ecosystem has not spread around much, probably due to the so-called "crypto-winter". As new big players are now entering the space, we are looking forward to the possibilities for providing new backends for the C3/System, like for the Libra network.
We will be soon releasing our ETH connector for Red. The final part missing is the integration of hardware and software key support for signing transactions on real online networks (we use private networks during development). The code for hardware key support is already there in our wallet, so we just need to integrate it inside the connector. For software keys, we have developed specific support for them, but it relies on third-party libraries, which are currently not a good match for our single binary distribution model.
GTK support
Red should offer soon a pretty good GUI backend for Linux, thanks to the community effort led by R cqls. The last PR for red/GTK branch weighs in at about 400 commits and covers most of View features.
The main remaining features to cover are:
Camera widget support (already available in an experimental branch)
Rich-text and Draw improvements
Shape dialect support
Some stability fixes
Here are some examples of scripts and apps using the GTK backend:
GTK theming is also supported:
Red/System
The ARM backend got many improvements:
Largely improved ARMhf (hard-float) support.
Fixes on regressions for ARMsf (soft-float).
Various libraries loading fixes, now all unit tests are passing again.
A few low-level features were added, that would make it easier to write device drivers or operating systems directly in Red/System:
Ability to save/reload all CPU registers on stack using intrinsics.
Ability to read/write CPU I/O ports using new intrinsics.
Ability to inline machine-code pretty much anywhere in R/S source code.
Replacing hard native support for modulo operation on floats by the soft fmod() import.
VSCode plugin
The Red plugin for VSCode got a major refresh with a full reimplementation using LSP model improving the efficiency of existing features and adding some new ones:
Smarter code completion
Realtime syntax checking
Goto definition support
Other WIP features JSON support
JSON format is now supported by Red's codec system. So it can be used in load/as and save/as to convert JSON data back and forth to Red values. More info about its usage in the Red 0.6.5 release notes.
Shadows in Draw
Some simple shadow effects in Draw have been implemented. They have the capabilities of the box-shadow model of CSS.
GPIO library for Raspberry Pi
Red has supported Raspberry Pi as a compilation target for many years, but we were still lacking a proper GPIO library, which is now under development. It will be implemented as a gpio:// port for now in the port-type branch. A dedicated library or dialect should be added also as a higher abstraction layer in order to simplify GPIO programming even further. Hobbyists and seasoned programmers will be able soon to build IoT projects on RPi easily using Red with GTK for the GUI support.
Next Red releases
0.6.5: Splitting the console and compiler
This is an important change that will be the new way to use Red and, hopefully, provide an even better experience, especially for newcomers. Not much coding is involved but we still need a prototype before giving the final go-ahead then proceeding with the code and infrastructure changes. We plan to finish those tasks during this summer (no precise ETA for now).
0.7.0: Full async I/O
Work started on this release many months ago but with a low-priority, as we have many other features to release first. The current state on the main features is:
port! type is almost completed and already usable (e.g. the eth:// port)
the native ports TCP, UDP, DNS should be implemented this summer.
the async API still needs design work before being implemented.
Tokens retro-distribution
We are setting up the last steps for the RED tokens retro-distribution (past contributions) and the first monthly distribution for new contributors. We will publish the first article in July that will provide all the rules that we have established for that process. Then shortly after, we will publish the list of the contributors who were selected according to those rules, with the reward amounts and proceed with the distribution (using the batch transactions feature of the RED Wallet).
For example, as part of our tokens rewarding program for contributors, R cqls should receive a good amount of them in the next distribution,
The road ahead...
The most notable next planned milestones are:
RED Wallet 0.4.0 in July.
C3/System alpha release in August!
Red/Android beta release in September!
Red/Pro for New year!
Red 64-bit will be split into two phases:
cross-compiled from 32-bit platform: end of the year
toolchain ported to 64-bit: 2020
We plan to give more information about each of those big new additions to the Red family this summer.
As several development tracks are coming to fruition in the next couple of months, new articles should come up more frequently.
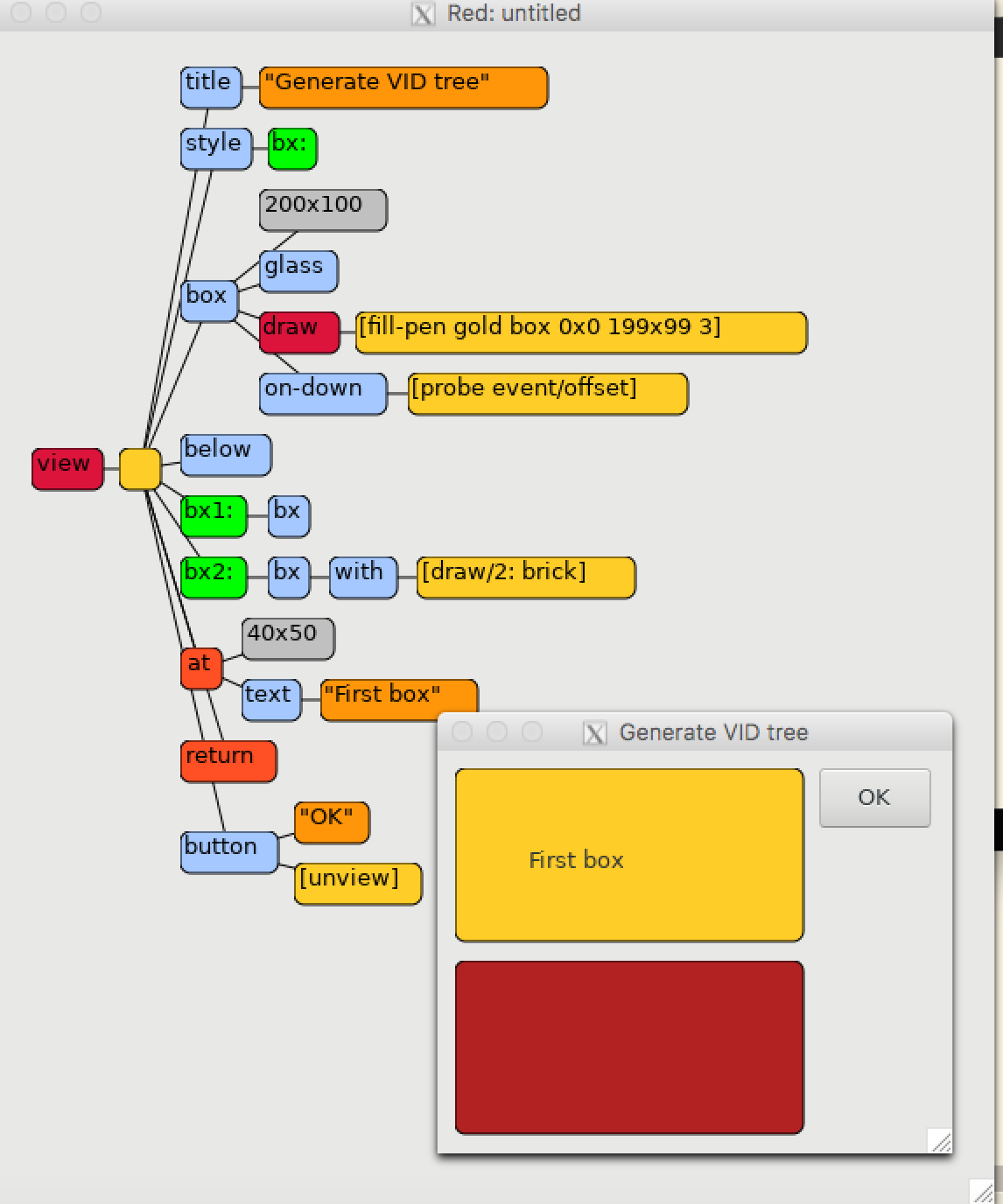
2019 started with continued advances in the main development branch, implementation of features, and triage of pending tickets. For example, smart merging of a style's actors with the actors of a particular face instance was introduced in the VID dialect. Example:
view [
style my-button: base
on-down [face/color: face/color / 2 do-actor face event 'click]
on-up [face/color: face/color * 2]
my-button "Say hi!" red on-click [print "hi"]
]
But this is just a tiny drop in the January ocean, and nothing special in the grand scheme of things. More than 50 commits to the mainline, lots of doc updates, and many improvements to the Red Wallet, which we'll talk about in another blog post. On the other hand, Red's progress is rarely trivial and silky smooth, and this write-up gives a deeper insight into our daily routine. Well, what did you expect, Pumpkin Juice? ;-)
Alas, as much as we love coding, organizational heavy-lifting needs to be done too — one of our short-term priorities this year is relocation of core team to Europe, and (ongoing) activity on this front took a lot of our time and resources in January. That is to say, after little overture, the core team's main activity shifted behind the scenes, giving the stage to our outstanding community's efforts. 1
Community highlights
GTK backend
Red strives to be a truly cross-platform language, but the project's roadmap always implies a certain order of priorities, where some milestones come later than others. One such missing cross-platform feature is the View engine's backend for Linux — its development requires dedicated resources, which the core team cannot fully afford, probably until near the 1.0 release.
With that in mind, it is much to our delight that development of GTK backend is being carried out as a dedicated community effort. We'd like to take an opportunity and thank all the people participating in it — their proactive contributions make Red a truly open-source project, and help us to advance it towards our collective vision. Big thanks to @rcqls for taking the lead on this.
Last but not least, you can track development's progress in a recently created GTK room. Don't forget to visit it and give our contributors all the praise they deserve! Or even better — become one of them and get a share of fame and glory! ;-)
View and Rich-text tweaking
Not only do missing parts of the View engine get developed, but existing ones receive thorough maintenance too. Features and fixes.
Among fixes are base and text rendering, Red's codebase received a contribution for testing of image-related features on Windows platforms, accompanied by more than 300 tests. Coupled with our "null" testing backend (covered in some detail in here) this casts a wide net for catching regressions in View.
As you can see from the above, native GUI support is one of our strongest aspects, which piques the interest of many community members.
Another special feature that catches everyone's fancy is Red's "code as data" nature. But, while giving Red enormous expressive power (metaprogramming and the creation of domain-specific languages, DSLs for short), it makes some things trickier — with the boundary between code and data being blurred, and multiple dialects (our term for embedded DSLs) at one's disposal, it is extremely challenging to assign any particular meaning to a given piece of code (data!); both for humans (esp. newr Red programmers) and automatic tools, such as syntax highlighters, static code analyzers, debuggers and linters.
Historically, this was the main argument when it came to Rebol's tooling. Sprinkling your code with print and probe is still the most common debugging method, and error reporting boils down to stack traces rather than source text info; text editing support can accommodate only cosmetic niceties like "keywords" highlighting and indentation, covering only general subset of the language.
Being a direct descendant of Rebol, we carried over this bag of concerns, aiming to resolve them at some point in development. A quite natural answer to points raised would be an editor written in pure Red and its dialects, integrated in our self-contained toolchain.
And while writing a basic version of such editor is rather trivial, such a naive approach leaves much to be desired, and keeps questions about proper tooling surrounded with an air of uncertainty, begging for a detailed investigation. Thankfully, this is where community projects and experiments come to the rescue!
@rebolek's Values, announced at last year's RedCon, is a sophisticated projectional editor with Vim's flavor and an ingenious schtick — rather than working with textual form, it loads a program and directly manipulates its internal data structure (a block! of values), reflecting all changes back in the text area.
Idiomatically written, and offering sheer power in a few keystrokes, it struck us in awe back at RedCon, and stimulated a lot of technical discussions. With our new GUI console's plug-in API on its way for 0.6.5 release, we are eager to see how it will get integrated in day-to-day user experience, and what fresh insights it can bring to all of us.
@toomasv is well-known in our community as an avid Draw and View tinkerer, and his recent experiment only firms this reputation.
Datatype-aware syntax highlighting, contextual help, auto-completion, step-by-step evaluation and bunch of other niceties — all in ~1K lines of code! Magic, you say? No, Reducing at its finest. ;-)
Projects like this (and all others that we didn't get a chance to mention) aren't just eye-candy for the public — they help us, core developers, to evaluate all options and to revisit old ideas in a new light. Besides, it's extremely rewarding to see Red (in its alpha stage) being put to real use.
Once again, our cheers go to all the people who dedicate their time and efforts to support us. No matter how small your contribution, it makes Red stronger and readier for the prime-time: day by day, bit by bit.
C3 project
Since the core team relocation is our ongoing No.1 priority, development of the C3 project got sidetracked a bit. There are still a few final touches that need to be done (e.g. finishing AST parser, hex! and bigint! datatypes support) but, aside from that, the first alpha version of compiler is almost ready for a public release. The first 90% of a task takes 90% of the time, the last 10% takes the other 90%.
In the meantime, we have one appetizer to serve: RedCon talk about C3! Due to technical issues and time constraints, it became available only recently, and was captured on a nearby web-camera. Because of that, video quality and recording angle are so-so, but the good news is that you can gain a deeper insight into the blockchain aspect of Red... and witness the talking belly. :-)
As evident from the talk2, C3's design proved to be much more challenging than we initially anticipated, muddled by pesky EVM (Ethereum Virtual Machine) constraints (like gas), lack of good reference documentation, complex tooling and blockchain hype haze.
At this point, we're convinced that at least two layers are required for C3 to be a sound smart-contract development solution:
The low-level one, named C3/System, is a language with simple semantics (close to Solidity, but without foot-shooting), serving as a base for building high-level dialects on top of it. We also want to implement a couple of experimental features, like off-chain Cron-like scheduler of Smart Contract execution and embedded FSM (finite-state machine) sub-dialect.
Possibly multiple high-level layers, each covering different blockchain aspect and tailored to specific solutions: creation of crypto tokens, gambling, in-game collectibles, legal contracts and business logic, bids and auctions, asset tracking... who-knows-what people may come up with.
Despite all the media craze surrounding blockchains, the technology itself is still in a nascent state, constantly searching for a real-world use-case. Because of that, navigating this new and constantly shifting space (not to mention building a development platform like C3) is like sailing in stormy weather.
In light of the above, we owe much to@9214 for his help with C3 preliminaries and conducting in-depth research on Smart Contract languages. His constant background presence affirmed many of our assumptions, and guided us past many reefs and pitfalls.
Back in the day, our "Red goes blockchain" announcement generated much controversy, and prompted many people (both community members and outsiders) to cast their doubts on this decision. Some go as far as to dismiss the Red project entirely, based on our new roadmap.
Yet, very few realize that, in some sense, we're picking up the game that Rebol left — with Carl's conception of X-Internet3 replaced by decentralized consensus-driven P2P networks, and EVM instead of IOS. Indeed, Smart Contracts are just very limited...slow Reblets/services in disguise ;-) And behind blockchain fatigue lies the brave new world, where Red can be the missing puzzle piece and stepping stone towards simple, human-friendly tooling.
All in all, we hold to our beliefs, and going to play this card, aiming to hit the jackpot. But we're also not putting all our eggs in one basket. Bear with us as we tread forward, and stay tuned for future updates!
Wrapping-up
January, with its holidays and family reunions, is nothing but a calendar sheet. The work on Red never ceases, spans through weekends, occupies all time and space (both physical and mental) and now reaches across the globe. For some, it became the animating principle of their lives.
With our hard work at stake, and with 1.0 release in near sight, encounters with the outside world get more frequent and progressively challenging — criticism and cross-checks with reality are important, but it's equally important to apply a fair yardstick, and judge the project on its own merits.
That's why, when it comes to media coverage and public discussions, we expect outsiders to stay open-minded and not to cast aspersions lightly. We want Red to succeed, and welcome technical debate and comparisons with other projects (like, e.g., Red vs. Racket; again, kudos to @9214 for writing such a well-articulated response). But, more often than not, discussion threads turn into exercises at damage control, with constructive points being hamstrung and torn to pieces in a cross-fire.
Our mission to fight software complexity is challenging, and not for the faint-hearted. Remember — the best way to prove one's case is not in word, but in deed... and the strongest argument is a tech-savvy pull-request. ;-)
Come to think of it, I can't help remembering Pierre Rabhi's tale:
Once upon a time, the scorching fire swallowed the forest. All the animals, terrified and powerless, watched it destroying their homes from afar. Only little Hummingbird kept flying back and worth between the fire and nearby pond, carrying tiny drops of water in its beak and throwing them in the flames.
Irritated by bird's constant flickering, grouchy Armadillo yelled: "Hummingbird! Don't you see that your pathetic attempts won't save the forest?"
"I know.", answered Hummingbird, "but I'm doing my part."
Hectic 2018 barely passed by, but we're already steering wheels on our new roadmap. There is more news to announce, once the dust has settled. We'll be in touch. Until then, Happy Reducing!
-- Post by 9214, edits and amendments by Gregg
Footnotes
Remember that you can track progress of Red projects (both community-driven and official ones) at https://progress.red-lang.org/
Reminder: C3 presentation slides in PDF format are available here.
It has been a tough year 2018, filled with roller-coasters and instability. The constant dropping of the crypto markets has forced us to change our plans pretty much every three months, in order to cope with that market uncertainty and our diminishing means. Though we have taken measures to ensure the proper funding for Red project for the next few years, so no worries on that side. All that has slowed down work on Red's core and even our new C3 language. That said we still have managed to make some great progress in the past year, e.g.:
RED Wallet released: a good showcase of what can be achieved in a small codebase using a truly full-stack programming language like Red, from USB and hardware keys drivers to blockchain network interfacing and cross-platform UI!
Garbage Collector: a simple mark & sweep, compacting GC for Red! That is a big step towards a completed production-ready Red version 1.0.
Red console fully re-implemented in Red itself, allowing new features like syntactic coloring and user plugins.
New rich-text display widget and related RTD dialect.
DPI-independent support for Red/View.
Preliminary port! and bigint! datatypes implementations.
eth:// port for interacting with the Ethereum blockchain (to be released publicly very soon).
Extended Red team with now about 12 people in total.
We are also working on structuring the Red Foundation and have a new recruit working on tokenomics. So the tokens retro-distribution to kick-start tokenomics should happen very soon.
The plan for 2019
We are starting the year with big targets as we need some last big pieces of the Red project to be implemented to reach both our technical and business goals. Here are the main tasks we will handle during this new year:
C3 toolchain release: the C3/System language spec was defined last October and work on the compiler and related toolchain is on-going. This is our main short-term priority as we want to test our business options in the smart contract market while it is still in its early days.
Red full async I/O support (0.7.0 milestone): we already have a PoC for async tcp/udp support, with Rebol-like event handling API. There is still a need for more design work (on-going right now) in order to provide the best possible API for Red users. For now, we are trying to avoid going full-force into the deep territory of defining a general concurrency support (it's scheduled for 0.9.0 milestone). I'm not yet sure if we can escape stepping into it anyway if we want to go beyond the Rebol async model.
Full Android support for Red: we have a preliminary implementation that has proven to be very promising! With the integration of async I/O and ports, we will be able to complete the wrapping of the Android API using decent human-friendly abstractions. We need to advance Android support to at least beta level by the end of this year. This is one of the major goals we need to achieve.
Red/Pro: it is coming this year! It will be our first commercial product and set of online services targetting both individual developers and enterprises. It will include a new backend for Red's toolchain, providing a state-of-the-art optimizing layer and support for many new platforms, including 64-bit ones (though full 64-bit Red support will probably be for next year). That new backend will provide an alternative to our current code emitter and linker, the rest of the toolchain remaining the same. The current Red toolchain will be known as the "community" version, and continue being the main development branch.
In addition to all that, a 0.6.5 milestone for Red is in the plans, aiming at making the Red console the main focus for Red users by providing:
prebuilt versions of the Red console.
ability to invoke the Red toolchain from the Red console.
a plugin API to extend the console in many ways.
In order to better focus on these tasks and better interact with our new team members in Europe, we will be relocating our core team from different parts of the world to Europe (Red Foundation is located in Paris). We also plan to make a RedCon2 developer conference in Europe later this year.
Many thanks to all the people who have contributed or helped in any way with advancing Red and managing the community. How do we climb the tallest mountain? One step at a time! And the top is in sight now, we're almost there. ;-)
Happy New Year to all, and keep up the great work you are all doing!